Ключевые инсайты исследования Anthropic: Индекс AI-флюентности
Аналитический обзор отчета «Anthropic Education Report: The AI Fluency Index»
О чём это исследование?
Anthropic опубликовала отчёт, посвящённый измерению AI-флюентности — способности людей эффективно и безопасно взаимодействовать с искусственным интеллектом. Исследование отвечает на критически важный вопрос: «По мере внедрения ИИ в повседневную жизнь, развивают ли пользователи навыки его грамотного использования?»
🔗 Оригинал исследования: https://www.anthropic.com/research/AI-fluency-index
Методология: как измеряли флюентность?
Исследователи использовали 4D AI Fluency Framework, разработанный профессорами Риком Даканом и Джозефом Феллером совместно с Anthropic. Фреймворк включает 24 поведенческих индикатора эффективного взаимодействия с ИИ.
Для анализа были отобраны 11 наблюдаемых поведений, которые можно зафиксировать в диалогах на платформе Claude.ai:
Категория
Примеры поведений
Итерация и уточнение
Построение на предыдущих ответах, уточнение запросов
Описание и делегирование
Чёткая формулировка цели, указание формата, приведение примеров
Оценка и критическое мышление
Проверка фактов, выявление недостающего контекста, вопросы к логике модели
📊 Объём выборки: 9 830 анонимизированных диалогов за 7 дней в январе 2026 года.
🎯 Два ключевых вывода исследования
Итерация = флюентность
85.7% диалогов демонстрировали итеративное взаимодействие — пользователи не принимали первый ответ, а уточняли и дорабатывали результат.
📈 Такие диалоги содержали в 2 раза больше индикаторов флюентности (2.67 против 1.33), в частности:
- В 5.6 раз чаще пользователи задавали вопросы к логике модели
- В 4 раза чаще выявляли недостающий контекст
✅ Инсайт: Глубокие, многораундовые диалоги — главный маркер зрелого использования ИИ.
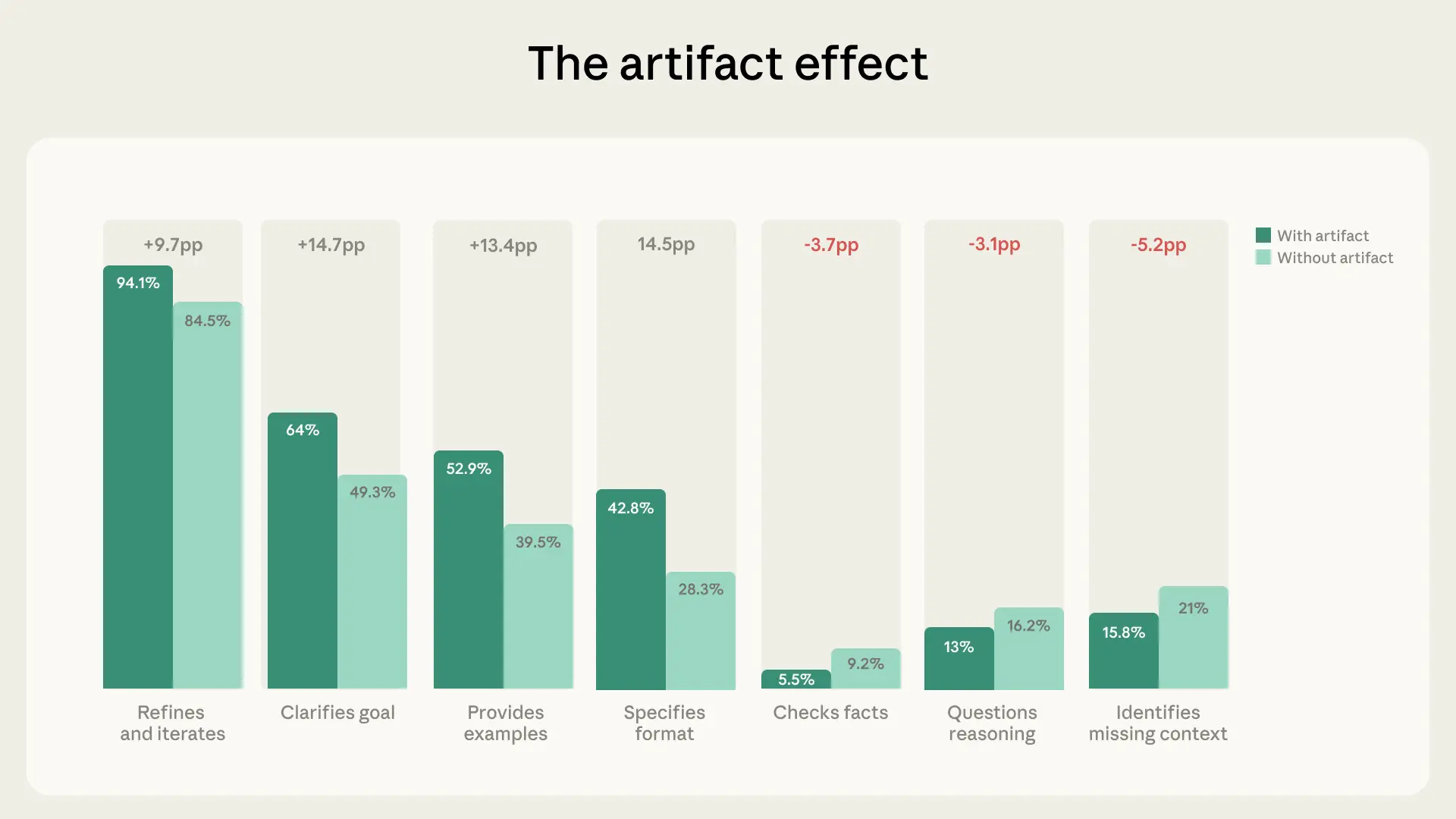
При создании артефактов критичность снижается
В 12.3% диалогов пользователи создавали артефакты: код, документы, приложения, интерактивные инструменты.
🔁 Что усиливалось:
- Уточнение цели (+14.7 п.п.)
- Указание формата (+14.5 п.п.)
- Приведение примеров (+13.4 п.п.)
- Итеративная доработка (+9.7 п.п.)
⚠️ Но критичность падала:
- Выявление недостающего контекста: −5.2 п.п.
- Проверка фактов: −3.7 п.п.
- Вопросы к логике модели: −3.1 п.п.
🔍 Гипотезы авторов:
- Готовый, «отполированный» результат создаёт иллюзию завершённости
- В задачах на визуал/функционал точность может восприниматься как менее критичная
- Пользователи могут проверять результат вне чата (запуск кода, тестирование)
❗ Важно: По мере роста качества генерации ИИ, критическая оценка становится не менее, а более важной.
Три рекомендации для развития AI-флюентности
На основе данных исследования Anthropic предлагает три практических направления для улучшения навыков работы с ИИ:
Рекомендация
Практический совет
Оставайтесь в диалоге
Не принимайте первый ответ как финальный. Задавайте уточняющие вопросы, оспаривайте сомнительные моменты, уточняйте контекст.
Критикуйте «красивые» результаты
Когда ИИ выдаёт визуально завершённый продукт — именно тогда стоит спросить: «Всё ли точно? Что упущено? Насколько обоснована логика?»
Задавайте правила сотрудничества
Только в 30% диалогов пользователи явно формулируют, как хотят, чтобы ИИ с ними взаимодействовал. Попробуйте: «Указывай, в чём не уверен», «Объясняй ход рассуждений перед ответом», «Оспаривай мои допущения, если они ошибочны».
Ограничения исследования
- Выборка: Пользователи Claude.ai, активные в одну неделю января 2026 — вероятно, early adopters, не репрезентативные для всей популяции
- Частичный охват фреймворка: Из 24 индикаторов проанализированы только 11 наблюдаемых в чате; этические и ответственные практики вне интерфейса не учтены
- Бинарная классификация: Поведение фиксировалось как «есть/нет», без учёта градаций и нюансов
- Неявные действия: Пользователи могут проверять факты или тестировать код вне чата — такие действия не фиксируются
- Корреляция ≠ причинность: Выявленные связи не доказывают, что одно поведение вызывает другое
Что дальше?
Anthropic планирует:
- Проводить когортный анализ — сравнивать новичков и опытных пользователей
- Использовать качественные методы для изучения «невидимых» поведений (этика, ответственность)
- Исследовать причинно-следственные связи: например, стимулирует ли итерация критическое мышление?
- Расширить анализ на Claude Code — платформу для разработчиков
«Мы ожидаем, что природа AI-флюентности будет существенно развиваться. Наша цель — сделать этот процесс видимым, измеримым и практически применимым».
Цитирование и ссылка на оригинал
Ссылка на оригинал:
BibTeX для цитирования:
@online{swanson2026aifluency,
author = {Kristen Swanson, Drew Bent, and Zoe Ludwig and Rick Dakan and Joe Feller},
title = {Anthropic Education Report: The AI Fluency Index},
date = {2026-02-16},
year = {2026},
url = {https://www.anthropic.com/news/anthropic-education-report-the-ai-fluency-index},
}
APA-стиль (для справки):
Swanson, K., Bent, D., Ludwig, Z., Dakan, R., & Feller, J. (2026, February 16). Anthropic Education Report: The AI Fluency Index. Anthropic. https://www.anthropic.com/research/AI-fluency-index
💬 Для кого это важно: Руководителям, внедряющим ИИ-инструменты в бизнес-процессы; HR и L&D-специалистам, разрабатывающим программы обучения; продуктовым командам, проектирующим UX для ИИ-взаимодействий.
Подготовлено на основе открытого отчета Anthropic. Не является официальным переводом или аффилированным материалом.
